

Existem diversos serviços de armazenamento de arquivos na nuvem, um dos mais usados é o S3 da Amazon. Veja a seguir como usá-lo na linguagem Python.
Criando usuário de acesso ao S3
Antes de começar é importante entender que será necessário criar uma conta de acesso, ou no caso da AWS, um usuário IAM que possui permissão de enviar arquivos ao S3.
Para criar o usuário IAM você precisa acessar seu console AWS e ir na área de IAM e criar um novo usuário, veja a imagem abaixo.
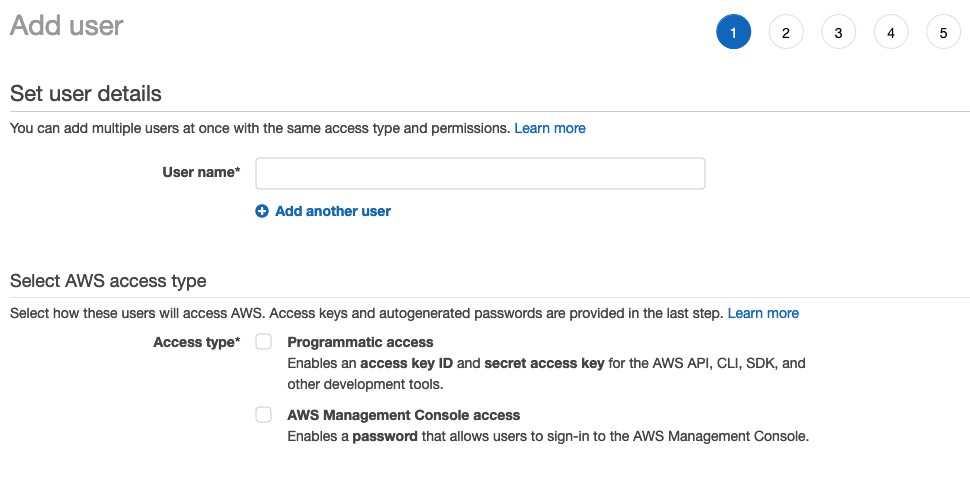
Coloque no campo “User name” um nome qualquer para o usuário, por exemplo “s3uploader”, e marque a opção “Programmatic access” para indicar que estamos criando um usuário com acesso somente a API da AWS.
Clique em “Next: Permissions” para adicionarmos as permissões ao nosso usuário. Nesse exemplo vamos adicionar as permissões diretamente ao usuário, para isso clique na tab “Attach existing policies directly” e no campo de busca digite “s3”, isso irá listar todas as permissões relacionadas ao S3. Selecione o item “AmazonS3FullAccess” e clique no botão “Next: Tags”, veja a imagem.
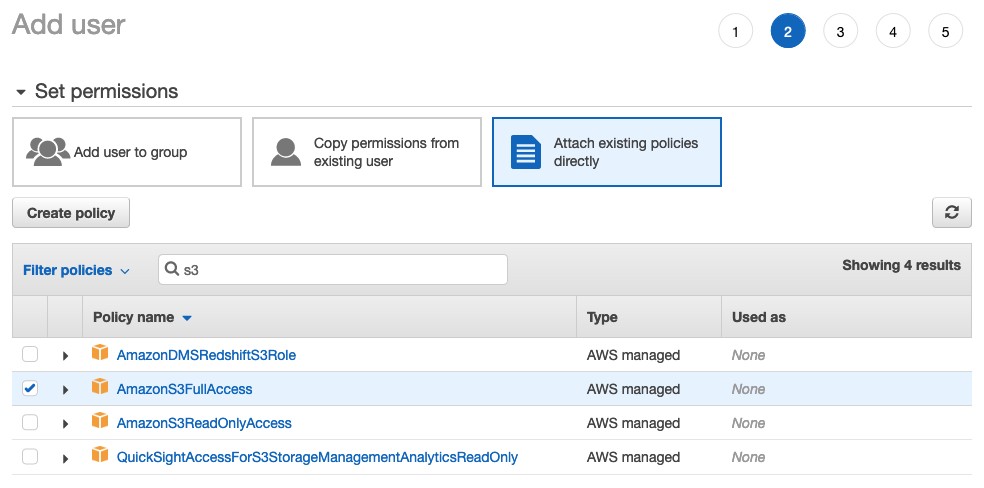
Não precisamos adicionar nenhuma tag ao nosso usuário, por isso na tela seguinte apenas clique em “Next: Review” e finalmente em “Create user”.
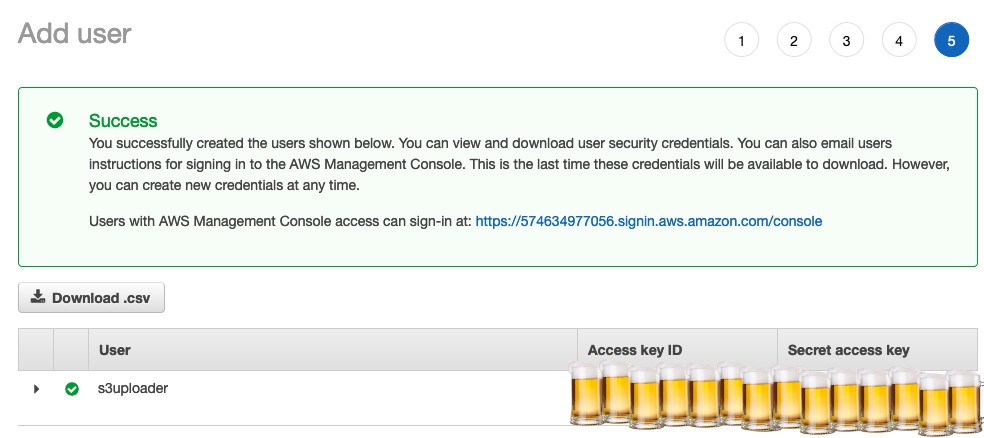
Se tudo ocorrer como esperado você verá uma página com os dados de “Access key ID” e “Secret access key”, salve estes dois valores pois iremos usar a seguir.
Enviando e recebemento arquivos do S3
Agora que temos nosso usuário, podemos enviar e receber arquivos ao S3, no caso de Python é comum usar a biblioteca boto3, uma biblioteca que pode ser usada não só para acessar o S3 mas diversos outros serviços da Amazon.
Para instalar a biblioteca basta executar no terminal:
| |
Observação: Se você nāo possuí o pip3 instalado veja este tutorial de como instalar.
Uma vez instalado, precisamos criar um cliente usando as credenciais do usuário que acabamos de criar.
| |
Com o cliente podemos realizar diversas operações, como criar um novo bucket.
| |
Usando a função create_bucket podemos criar um novo bucket. No exemplo acima estamos criando um bucket com acesso private, ou seja, apenas nosso usuário tera acesso ao bucket. Além disso, estamos dando um nome para o bucket, tenha em mente que este nome é compartilhado entre todos os usuários da região do seu bucket, por isso é necessário que o nome seja único, altere para o nome que quiser. Por fim precisamos definir a região aonde queremos que nosso bucket exista, no exemplo estamos colocando em eu-west-1 que fica na Irlanda (mais especificamente em Dublin), você pode usar qualquer região aqui. Dependendo da natureza da sua aplicação pode ser que você queira uma menor latência, nesse caso, é importante manter em uma região próxima aos seus usuários. Caso você queira um custo reduzido você pode tentar regiões onde o custo por GB é menor. Veja a tabela de custos do S3 para mais detalhes.
Criado nosso bucket, podemos acessar o console da nossa conta na AWS e acessar a página do S3 na região que criamos o bucket, podemos ver que o bucket foi criado com sucesso.
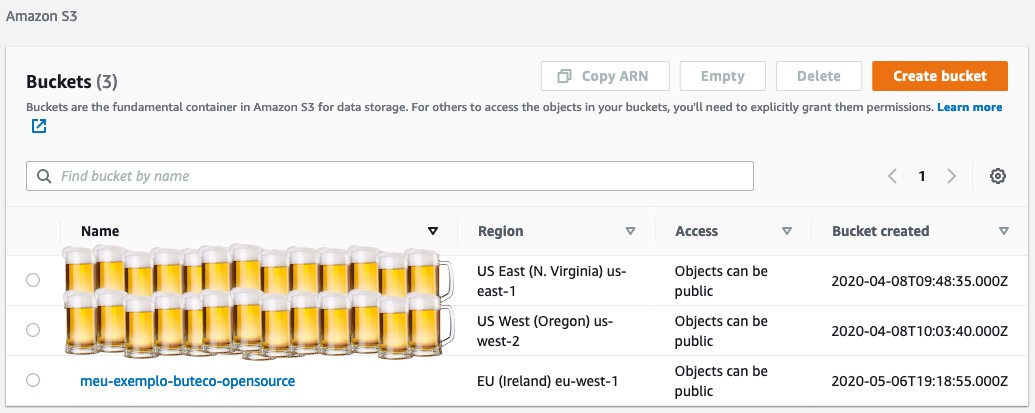
Agora que confirmamos que nosso bucket foi criado, vamos fazer o primeiro upload, mas antes vamos criar um arquivo de texto com um conteúdo qualquer.
| |
Gravando o conteúdo “Olá, S3!” num arquivo hello-s3.txt podemos fazer o upload dele para o S3 da seguinte maneira.
| |
O metodo upload_file precisa de 3 parâmetros, o primeiro é o caminho para o arquivo que queremos fazer upload, o segundo é o nome do bucket e o último é o nome da chave do arquivo no S3. Acessando novamente o S3 e entrando no bucket que criamos conseguimos confirmar que o arquivo foi “upado” com sucesso.
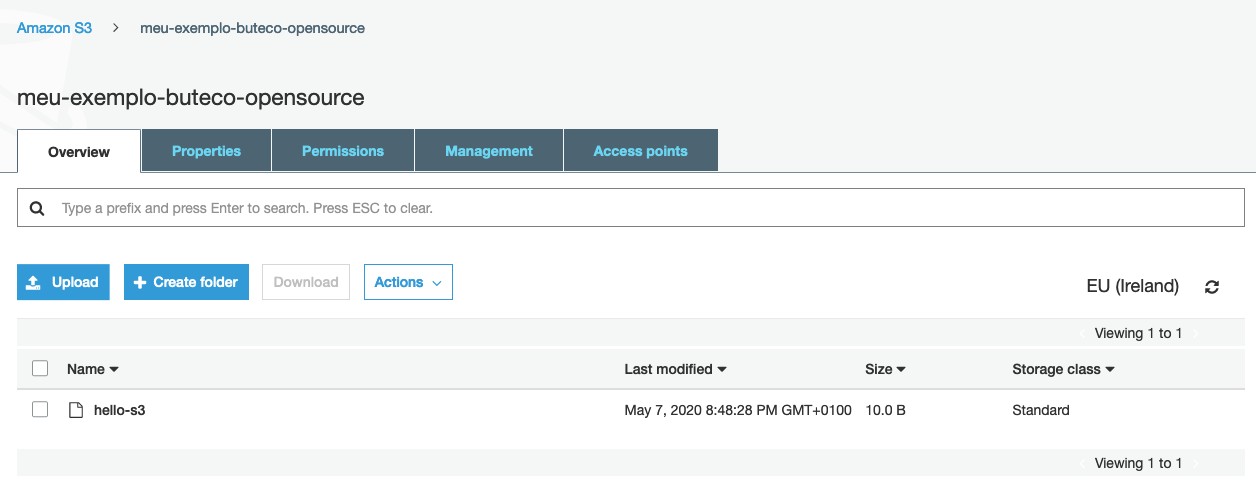
Confirmado o upload, podemos tentar fazer o download e imprimir o conteúdo do arquivo.
| |
Para isso usamos o método download_file que precisa de 3 parâmetros, o primeiro é o nome do bucket, o segundo é a chave do objeto que queremos fazer o download, no nosso caso “hello-s3”, e por último o nome do arquivo local que recebera o conteúdo do arquivo do S3.
Executando com sucesso o código acima, é esperado que você tenha um arquivo chamado “downloaded-hello-s3.txt” com o conteúdo original que criamos nos passos anteriores.
Conclusão
Podemos ver que é bastante simples usar o S3 da Amazon, podemos aplicar isso em diversos tipos de aplicações e ao usar outros recursos do S3 como deixar o bucket público, conseguimos hospedar arquivos estáticos que podem ser acessados por qualquer pessoal, isso é especialmente útil para aplicações de streaming, CDN e muitas outras.
Gostou do artigo? Gostaria de ler mais sobre? Ficou alguma duvida? Teve algum erro? Comente e deixe sua opinião.
Até a próxima.