
Logstash basicamente é uma ferramenta de extração de dados, seu uso é simples, você determina um entrada (input), extrai informações que atendem a um padrão com filtros (filters) e gera uma saída (output), o famoso “entrada -> processo -> saída”. Seguindo esse conceito base, para cada etapa, o logstash possuí vários “plugins” que são pequenos programas que fazem as integrações do logstash, cada etapa possuí seus plugins, o que faz com que você possa fazer a entrada, processo e saída de várias formas diferentes.
Para entender melhor esse conceito irei exemplificar a seguir, porém, antes de mais nada vamos fazer a instalação do logstash.
Instalação A processo de instalação é bem simples, você pode fazer o download no site oficial ou executar os comandos abaixo mudando os parâmetros conforme sua necessidade.
wget https://download.elastic.co/logstash/logstash/logstash-2.3.2.tar.gz
tar -xvf logstash-2.3.2.tar.gz
sudo ln -s /caminho_para_pasta_logstash-2.3.2/bin/logstash /usr/local/bin/logstash
Caso nenhum erro ocorra você terá agora acesso ao comando “logstash”, teste executando “logstash –help”, veremos agora um primeiro exemplo.
Exemplo 1: Lendo e escrevendo no terminal
O primeiro exemplo que irei demonstrar será o de ler e escrever no próprio terminal. Toda vez que você utilizar o logstash será preciso passar como parâmetro um arquivo de configuração, tipicamente com extensão ".cnf", que determinará o que o logstash deve fazer, segue abaixo a configuração do exemplo citado.
input { stdin { } } output { stdout {} }
Salve o texto acima em um arquivo nome qualquer como “pipeline.conf” e rode o seguinte comando.
logstash -f pipeline.conf
Você vai perceber que o programa não termina de executar, digite algo no terminal e aperte enter, algo como a imagem abaixo será exibido.
[caption id="" align=“aligncenter” width=“500”] Exemplo 1: Lendo e escrevendo no terminal[/caption]
Exemplo 1: Lendo e escrevendo no terminal[/caption]
Exemplo 2: Lendo um arquivo e extraindo dados
No segundo exemplo que veremos iremos ler de um arquivo de texto e imprimir na saída o resultado que obtivemos.Assim como no exemplo anterior precisaremos criar um arquivo de configuração, vamos dar o nome de “extractPipeline.conf”, abaixo segue o conteúdo inicial deste arquivo adaptado do exemplo anterior.
input {
file {
path => “/caminho/absoluto/para/arquivo.log”
start_position => beginning
ignore_older => 0
}
}
output {
stdout {}
}
Observe que adicionamos o plugin “file”, como o próprio nome diz, este é um plugin para fazer leituras de arquivos, dentro desta tag podemos passar alguns parâmetros, o principal é “path” que é o caminho absoluto para o arquivo que queremos ler, o segundo é “start_position” que indica ao logstash por onde deve começar a leitura, por padrão ele apenas monitora novas entradas no arquivo, algo semelhante ao comando “tail -f” do Linux, por último temos o parâmetro “ignore_older” isto é necessário pois por padrão o plugin considera arquivo com a data de modificação até 86400 segundos anteriores a data e hora atual. Para este exemplo criei um arquivo com o seguinte conteúdo.
linha 1
linha 2
linha 3
Rodando o comando “logstash -f extractPipeline.conf” teremos a seguinte saída.
Caso precise rodar mais vezes será necessário abrir e salvar o arquivo de entrada, nesse caso “arquivo.log” para que o logstash detecte a mudança na data de modificação do arquivo e execute novamente, como utilizamos a tag “start_position” como “beginning” ele sempre fará a leitura a partir do começo do arquivo, do contrário apenas irá considerar as novas linhas.
[caption id="" align=“aligncenter” width=“424”]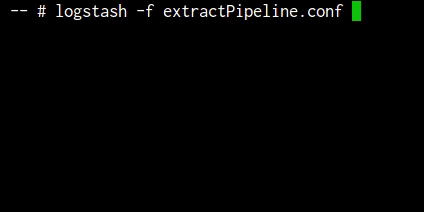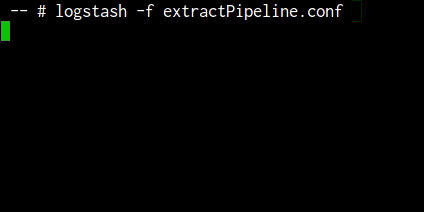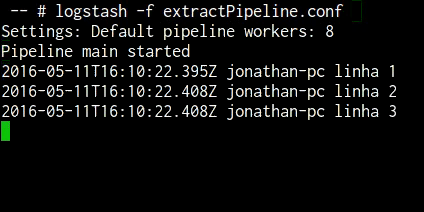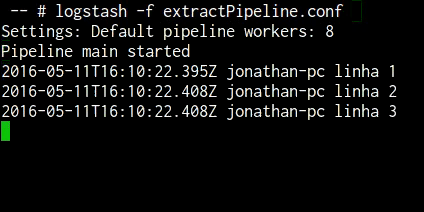 Exemplo 2: Lendo um arquivo e extraindo dados[/caption]
Exemplo 2: Lendo um arquivo e extraindo dados[/caption]
A próxima etapa será extrair alguma informação mais útil deste arquivo, vamos então começar a trabalhar com filtros, um filtro bastante comumente usado é o “grok”, este utiliza de regex para extrair informações de textos.
Para entender melhor como o grok funciona vamos a alguns exemplos de sua sintaxe, considere o seguinte texto em um arquivo.
[2016-05-16 16:50:00] ERROR: Call to undefined function "helloWorld()"
Para poder extrair corretamente as informações precisamos determinar qual o padrão da mensagem, nesse caso podemos dizer que o padrão é algo como.
[ano-mes-dia hora:minutos:segundos] level: mensagem
A partir desse processo de identificação do padrão podemos “traduzir” esse padrão para a sintaxe do grok.
[[]%{YEAR:ano}[-]%{MONTHNUM:mes}[-]%{MONTHDAY:dia}[s]%{HOUR:horas}[:]%{MINUTE:minutos}[:]%{SECOND:segundos}[]][s]%{LOGLEVEL:nivel}[:][s]%{GREEDYDATA:mensagem}
Não se assuste, vamos por partes, primeiramente acesse o site grokdebug, nele poderemos testar nosso script antes e enviar ao logstash, insira as informações conforme a imagem.
[caption id="" align=“aligncenter” width=“800”]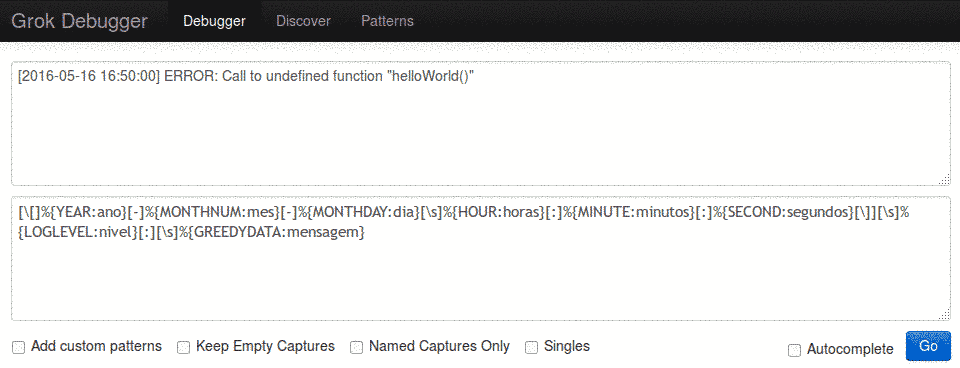 Exemplo 2: Lendo um arquivo e extraindo dados[/caption]
Exemplo 2: Lendo um arquivo e extraindo dados[/caption]
{
"ano": [
[
"2016"
]
],
"mes": [
[
"05"
]
],
"dia": [
[
"16"
]
...
Esta é a saída do processamento da entrada pelo filtro, podemos redirecionar para um outro filtro ou para uma saída, definida pela tag “output”, mas antes vamos adicionar o filtro a nossa configuração, segue o conteúdo do arquivo.
input {
file {
path => "/caminho/absoluto/para/input.log"
start_position => beginning
ignore_older => 0
}
}
filter {
grok {
match => { "message" => "[[]%{YEAR:ano}[-]%{MONTHNUM:mes}[-]%{MONTHDAY:dia}[s]%{HOUR:horas}[:]%{MINUTE:minutos}[:]%{SECOND:segundos}[]][s]%{LOGLEVEL:nivel}[:][s]%{GREEDYDATA:mensagem}" }
}
}
output {
stdout {}
}
E claro, este é o conteúdo do arquivo de entrada que utilizaremos para esse exemplo.
[2016-05-16 16:50:00] ERROR: Call to undefined function "helloWorld()"
[2016-05-16 16:55:00] ERROR: Call to undefined function "helloWorld()"
[2016-05-16 17:00:00] ERROR: Call to undefined function "helloWorld()"
Executando temos o seguinte resultado.
[caption id="" align=“aligncenter” width=“800”] Exemplo 2: Lendo um arquivo e extraindo dados[/caption]
Exemplo 2: Lendo um arquivo e extraindo dados[/caption]
output {
stdout {}
csv{
fields => [“ano”,”mes”,”dia”,”horas”,”minutos”,”segundos”,”nivel”,”mensagem”]
path => “/caminho/absoluto/para/output.csv”
}
}
Rode novamente o comando e o seguinte conteúdo deve aparecer no arquivo “output.csv”
2016,05,16,16,50,00,ERROR,”Call to undefined function “”helloWorld()”””
2016,05,16,16,55,00,ERROR,”Call to undefined function “”helloWorld()”””
2016,05,16,17,00,00,ERROR,”Call to undefined function “”helloWorld()”””
Perceba que cada valor está dividido por uma vírgula, a sequencia dos valores é determinada pela sequencia da tag “fields” passada na configuração.
Conclusão
Podemos concluir que o logstash é uma ótima alternativa para o processamento e extração de dados, a ferramenta é gratuita e pode ser integrada com outras como o Elasticsearch e Kibana, ambos da mesma empresa que criou o logstash.Você conhecia o logstash ? Utiliza em alguma aplicação? Diga nos comentários :)