
Pipes e FIFOs são muito utilizados no mundo Linux como um método de IPC (inter process communication), ou comunicação entre processos. Muitas das vezes nem percebemos que estamos usando-os pela sua facilidade. Normalmente usamos pipes no shell, como no comando abaixo:
ls | wc -lNeste comando, o shell executa o comando ls, pegando todo o conteúdo de saída e o direciona para a entrada do processo wc, que é criado logo em seguida, tudo de um jeito simples de escrever.
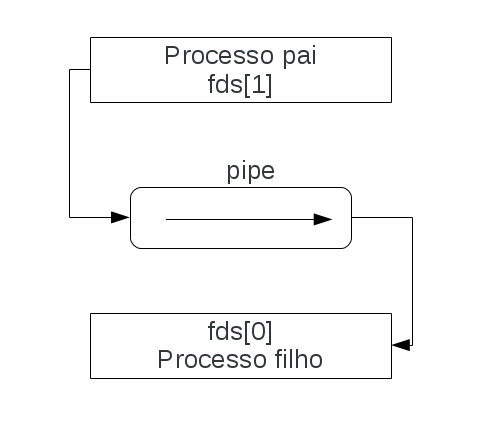
Pipes na verdade agem como "canos" que conectam processos unidirecionalmente. Ou seja, todo o pipe tem um lado que escreve dados e outro que lê estes dados. Vejamos o código abaixo onde mostramos onde dois processos leem e escrevem no pipe recém-criado:
É um código um pouco extenso de começo, mas após a explicação ele se torna de fácil leitura. Aqui podemos verificar que a chamada de sistema pipe é executada, recebendo como parâmetro um array de inteiros de duas posições. Se a chamada for executada com sucesso, o array de inteiros terá dois files descriptors para o pipe. A posição zero do array contém o fd de leitura do pipe, e a posição um contém o fd de escrita.
Podemos verificar que após a chamada pipe ser executada, um fork é feito. O fork nada mais é que a criação de um novo processo, onde este novo processo começa a executar do ponto em que foi executado o fork. O retorno da chamada fork é utilizado para identificar qual processo é o pai e qual é o filho. Desta forma um switch-case é utilizado para separar os trechos de código que devem ser executados pelo processo pai e processo filho. Neste momento não é possível saber qual dos dois processos irá executar primeiro, pois os dois são concorrentes perante a CPU.
Explicado o fork, podemos nos atrelar ao real funcionamento do exemplo, onde o processo pai irá escrever uma mensagem no pipe, e esta mensagem deve ser lida pelo processo filho. Após o fork, o processo pai fecha o file descriptor de leitura, e o processo filho fecha o file descriptor de escrita, uma vez que o processo pai somente irá escrever no pipe e o processo filho irá fazer a leitura. Neste ponto, o processo filho executa a chamada read que lê dados do file descriptor de leitura do pipe, e então o processo filho fica esperando por dados a serem lidos. Ao mesmo tempo, o processo pai escreve uma mensagem utilizando o file descriptor de escrita utilizando a chamada de sistema write.
Toda esta informação junta pode dar uma certa confusão no inicial. Para fins de simplificar o exemplo, abaixo consta como compilar e executar o programa, e a saída do mesmo.
Para compilar, invocamos o GCC: gcc pipe.c -Wall -o pipeExecuntado e mostrando a saída do exemplo: marcos@localhost: [pipe_fifo] # ./pipe Parent wrote the message! Child readed: Hello from parent! Have a long life!
Você pode alterar o código e verificar a saída do mesmo para um melhor entendimento do que realmente acontece.
Alguns pontos interessantes sobre o uso de pipes:
- Se mais de um processo ou thread está escrevendo no pipe ao mesmo tempo, o kernel assegura que as escritas serão atômicas, ou seja, não haverá interrupções de escritas, desde que o número de bytes escritos seja menor ou igual PIPE_BUF. Esta definição está dentro do arquivo /usr/include/linux/limits.h e no meu sistema ele tem o valor de 4096.
- A capacidade de um pipe de reter informação é limitada. Desde a versão 2.6.11 do Linux o limite de dados que um pipe pode armazenar é 65536 bytes. Mas, uma vez que uma aplicação for bem desenhada e que o lado de leitura do pipe consiga ler assim que o dado está disponível, não haverá problemas com esta limitação.
- Pipes podem somente ser usados por processos afiliados, ou seja, processos pai com processos filhos, netos e etc. Existe um tipo de pipe que pode ser usado por processos diferentes. Este se chama FIFO e será abordado nas próximas postagens.