

Apache Parquet é um formato de armazenamento colunar disponível em todos os projetos que pertencem ao ecossistema Hadoop, independente do modelo de processamento, framework ou linguagem usada.
O projeto iniciou em uma parceria entre o Twitter e a Cloudera, e a primeira versão foi liberada em 2013. Desde 2015 o projeto faz parte da Apache Software Foundation.
Diferente dos modelos tradicionais de armazenamento que usam abordagem orientada a linhas, o Parquet armazena os dados de forma colunar plana, onde os valores das colunas são armazenadas de forma adjacente as outras, esse modelo possui alguns benefícios:
- Compressão por colunas é mais eficiente
- Algorítimo de compressão pode ser especificado por coluna
- Queries “wide” (que usam várias colunas) são mais eficientes
Parquet foi criado para suportar compressão e codificação de forma eficiente, sendo possível especificar compressão por coluna, além de ser otimizado para trabalhar com estruturas de dados complexas em massa. Todos esses benefícios são em virtude do algorítimo record shredding and assembly algorithm descrito no Dremel paper da Google e implementado como parte do core do Parquet.
Podemos dividir um arquivo Parquet em duas partes basicamente:
- Dados
- Metadados
Na parte de dados ainda podemos descrever os seguintes itens:
- Row group — Particionamento lógica dos dados em linhas
- Column chunk — Um chunk de dados em uma coluna em particular
- Page — Column chunk também são divididos em páginas
Já na parte de metadados temos dados como versão, informações sobre as colunhs, entre outras informações que são utilizadas durante a leitura do arquivo.
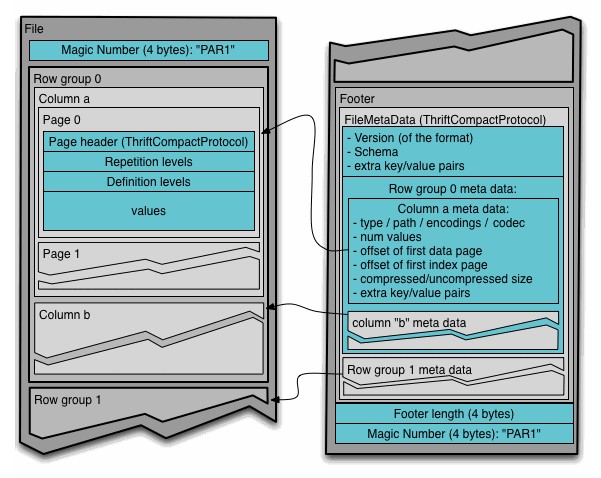
Estrutura de um arquivo Parquet
Em um comparativo disponibilizado pela Databricks em relação ao uso de CSV ou Parquet podemos observar:
| Formato | Espaço utilizado | Tempo de execução | Escaneado |
|---|---|---|---|
| CSV | 1 TB | 236 seg | 1.15 TB |
| Parquet | 130 GB | 6.78 seg | 2.51 GB |
O uso de Parquet reduziu o espaço de armazenamento em 87%, escaneou 99% menos dados e executou 34x mais rápido em determinadas operações.
É possível utilizar Parquet em diversas ferramentas do ecossistema Hadoop como, por exemplo:
Mas chega de teoria, vamos colocar a mão na massa.
No exemplo de hoje vou explicar como utilizar Parquet com Pandas e Spark.
Pandas
O Pandas é uma biblioteca para análise e manipulação de dados em Python.
Neste exemplo vamos converter uma lista de dicionários, salvar no formato Parquet e após vamos carregar o arquivo gerado para conferência.
import pandas as pdpessoas_df = pd.DataFrame([
{"nome":"Pedro", "idade": 15},
{"nome":"João", "idade":30},
{"nome":"Maria", "idade":19},
{"nome":"Marcelo", "idade":18},
{"nome":"Alex", "idade":38},
{"nome":"Otavio", "idade":44},
{"nome":"Ricardo", "idade":23},
{"nome":"Camila", "idade":12},
{"nome":"Alice", "idade":24},
{"nome":"Marlei", "idade":32},
{"nome":"Marilene", "idade":56},
{"nome":"Judite", "idade":60},
])print(pessoas_df) nome idade
0 Pedro 15
1 João 30
2 Maria 19
3 Marcelo 18
4 Alex 38
5 Otavio 44
6 Ricardo 23
7 Camila 12
8 Alice 24
9 Marlei 32
10 Marilene 56
11 Judite 60
pessoas_df.to_parquet("./pessoas.pq")parquet_df = pd.read_parquet("./pessoas.pq")print(parquet_df) nome idade
0 Pedro 15
1 João 30
2 Maria 19
3 Marcelo 18
4 Alex 38
5 Otavio 44
6 Ricardo 23
7 Camila 12
8 Alice 24
9 Marlei 32
10 Marilene 56
11 Judite 60
Spark
O Spark é uma engine para processamento e análise de dados, e o exemplo é bem simples.
Vamos usar o Spark para salvar um DataFrame no formato Parquet, após salvo vamos carregar o arquivo gerado e executar queries SQL em cima dos dados.
from pyspark.sql import SparkSession, Rowspark = SparkSession.builder.appName("demo-app").getOrCreate()pessoas_df = spark.createDataFrame([
Row(nome="Pedro", idade=15),
Row(nome="João", idade=30),
Row(nome="Maria", idade=19),
Row(nome="Marcelo", idade=18),
Row(nome="Alex", idade=38),
Row(nome="Otavio", idade=44),
Row(nome="Ricardo", idade=23),
Row(nome="Camila", idade=12),
Row(nome="Alice", idade=24),
Row(nome="Marlei", idade=32),
Row(nome="Marilene", idade=56),
Row(nome="Judite", idade=60),
])pessoas_df.write.parquet("pessoas.parquet")parquet_df = spark.read.parquet("pessoas.parquet")parquet_df.createOrReplaceTempView("pessoasView")todas_pessoas = spark.sql("SELECT nome, idade FROM pessoasView")
todas_pessoas.show()+--------+-----+
| nome|idade|
+--------+-----+
| Ricardo| 23|
| Marcelo| 18|
| Marlei| 32|
|Marilene| 56|
| Judite| 60|
| Pedro| 15|
| Camila| 12|
| Alice| 24|
| Alex| 38|
| Otavio| 44|
| João| 30|
| Maria| 19|
+--------+-----+
maiores_de_idade = spark.sql("SELECT nome, idade FROM pessoasView WHERE idade >= 18")
maiores_de_idade.show()+--------+-----+
| nome|idade|
+--------+-----+
| Ricardo| 23|
| Marcelo| 18|
| Marlei| 32|
|Marilene| 56|
| Judite| 60|
| Alice| 24|
| Alex| 38|
| Otavio| 44|
| João| 30|
| Maria| 19|
+--------+-----+
spark.stop()Conclusão
O artigo de hoje foi mais para explicar o que é Parquet e porque ele pode ser uma melhor alternativa de armazenamento em comparação a CSV e JSON.
Se você já faz uso de ferramentas como Spark ou outras da Apache, será inevitável uma migração no futuro para um ganho em desempenho.
A única desvantagem que eu vejo em comparação a outros formatos é que Parquet é um formato binário, sendo assim, é necessária alguma ferramenta externa para visualizar os dados, no caso de CSV ou JSON basta abrir em algum editor de texto, ou planilha, mas tecnicamente isso irá funcionar apenas para arquivos pequenos.
Dúvidas ou sugestões? Deixe um comentário.
Notebooks
Referências